SuryaKant Patidar / skp skp (at) skp (dot) co (dot) in http://skp.co.in |

|
SuryaKant Patidar / skp skp (at) skp (dot) co (dot) in http://skp.co.in |
|
Scalable Primitives for Data Mapping and Movement on the GPU, Suryakant Patidar, MS Thesis, CVIT, IIIT Hyderabad, 2009. [pdf 2.7MB]Publications
Suryakant Patidar, P. J. Narayanan. Scalable Split and Sort Primitives using Ordered Atomic Operations on the GPU, High Performance Graphics (Poster), April 2009. [pdf 328KB]
Vibhav Vineet, Harish P K, Suryakant Patidar, P. J. Narayanan. Fast Minimum Spanning Tree for Large Graphs on the GPU, High Performance Graphics, April 2009. [pdf 596KB]
Kishore K, Rishabh M, Suhail Rehman, P. J. Narayanan, Kannan S, Suryakant Patidar. A Performance Prediction Model for the CUDA GPGPU Platform. International Conference on High Performance Computing, Dec 2009. [pdf 334KB]
Suryakant Patidar, P. J. Narayanan. Ray Casting Deformable models on the GPU, In Proceedings of the 7th Indian Conference on Computer Vision, Graphics and Image Processing, Dec 2008. [pdf 1.2MB] [video 5MB]
Shiben Bhattacharjee, Suryakant Patidar, P. J. Narayanan. Real-time Rendering and Manipulation of Large Terrains, In Proceedings of the 7th Indian Conference on Computer Vision, Graphics and Image Processing. Dec 2008. [pdf 644K] [video 47MB]
Soumyajit Deb, Shiben Bhattacharjee, Suryakant Patidar, P. J. Narayanan. Real-time Streaming and Rendering of Terrains In Proceedings of the 6th Indian Conference on Computer Vision, Graphics and Image Processing. Dec 2006. [pdf 741KB] [video 19MB]
Suryakant Patidar, Shiben Bhattacharjee, Jag Mohan Singh, P. J. Narayanan. Exploiting the Shader Model 4.0 Architecture, IIIT/TR/2007/145, March 2007. [pdf 509KB]
Scalable Split/Sort and Gather Primitives for the GPU
We present efficient implementations of two primitives for data mapping and distribution on the massively multithreaded architecture of the GPUs in this paper. The split primitive distributes elements of a list according to their category. Split is an important operation for data mapping and is used to build data structures, distribute work load, etc., in a massively parallel environment. The gather/scatter primitive performs fast, distributed data movement. Efficient data movement is critical to high performance on the GPUs as suboptimal memory accesses can pay heavy penalties. The split we implement is a generalization of the binary split [Blelloch 1990] and is implemented using the shared memory and the atomic operations available on them. The split performance scales logarithmically with the number of categories, linearly with the list length, and linearly with the number of cores on the GPU. This makes it useful for applications that deal with large data sets. We also present a variant of split that partitions the indexes of records. This facilitates the use of the GPU as a coprocessor for split or sort, with the actual data movement handled separately. We can compute the split indexes for a list of 32 million records in 180 milliseconds for a 32-bit key and in 800 ms for a 96-bit key. The instantaneous locality of memory references play a critical role in data movement on the current GPU memory architectures. For scatter and gather involving large records, we use collective data movement in which multiple threads cooperate on individual records to improve the instantaneous locality. The split, gather, and their combinations find many applications and expect our primitives will be used by future GPU programmers. We show sorting of 16 million 128-byte records in 379 milliseconds with 4-byte keys and in 556 ms with 8-byte keys.
Ray Casting Deformable Models on the GPU
The GPUs pack high computation power and a restricted architecture into easily available hardware today. They are now used as computation co-processors and come with programming models that treat them as standard parallel architectures. Ray casting is an inherently parallel and highly compute intensive operation. We explore the problem of real time ray casting of large deformable models (over a million triangles) on large displays (a million pixels) on an off-theshelf GPU in this paper. We build a GPU-efficient threedimensional data structure for this purpose and a corresponding algorithm that uses it for fast ray casting. We also present fast methods to build the data structure on the SIMD GPUs, including a fast multi-split operation. We achieves real-time ray-casting of a million triangle model onto a million pixels on current Nvidia GPUs using the CUDA model. Results are presented on the data structure building and ray casting on a number of models. The ideas presented here are likely to extend to later models and architectures of the GPU as well as to other multi core architectures.


Exploiting the Shader Model 4.0 Architecture
The Direct3D10/SM4.0 system is the 4th generation. programmable graphics processing units (GPUs) architecture. The new pipeline. introduces significant additions and changes to prior generation pipeline. We explore these new features and experiment to judge their performance. The main facilities introduced that we ponder upon are, Unified Architecture providing common features set for all programmable stages, Geometry Shader which is a new programmable stage capable of generating additional primitives, Stream output with which primitive data can be streamed to memory, Array textures and primitive level redirection to different frame buffers through layered rendering. We analyze our implementations and with experimentation, we draw conclusions on their efficient usage and provide some of their limitations. We thus present a number of applications viz. Rendering Geometry Images, Two-level Culling,. Subdivision on Geometry Shader, Multiple Dynamic Light Shadows, Motion Blur. using Layered Rendering, Interactive Physics on Terrains..


Infinite GPU resident terrains
Terrains are large geometric objects and provide many challenges for real-time rendering and interactive editing. We describe a representation. which is built upon regular tiles for terrains usingFixed-in-Memory Tiles (FMT) , a fixed-size grid of height values. FMTs have a fixed memory size, but the resolution depends on the view distance. The terrain is cached on the GPU in terms of blocks of FMTs at an appropriate resolution and is rendered from it. We use a novel 2-level frustum culling scheme in which the geometry shader culls the tiles in terms oftilelets . The CPU load is kept low by sending points from the CPU and expanding each into a tilelet in the geometry shader. The GPU cache is updated as the viewpoint changes to keep it roughly lefted around the viewing area. The tiled structure of the. terrain representation allows modification and editing of the terrain. as well as computing interactions with other objects with low CPU involvement..


A Terrain Visualization/Information System using Height Maps and Satellite Images
This was my Final Year Project during my undergraduation. It dealt with coming up with a Visualization/Information System for Terrains which supports features like Adding Real Time Annotations, Stereo Vision and Automated Flythroughs. It was done using OpenGL and SDL.


Streaming an MPEG video over wireles LAN from a server to PDAs
This project dealt with streaming of MPEG videos over wireless LAN from a PC server to PDA(s) in the vicinity. The objective of project was to stream videos at variable bitrates. The user should be allowed to change the Bitrate (quality) of the incoming stream based on the capabitlities of his handheld. We used VLC as the streaming tool and hacked it to satisfy the requirements of the project. The PDA used was Sharp Zaurus SL and the player on the PDA was vlc which was cross-compiled for the PDA.
Morphing Toolkit
A Morphing toolkit was creted using Matlab both as back end as well as front end for the course of Digital Image Processing. This was my first project in the field of Image Processing. The toolkit supports 3 main functionalities of Adobe Photoshop viz. Bloating, Puckering and Twirling. An algorithm named Beir Neely Algorithm was used to come up with the warp effects.


3-D Model of a Room and Mirror Simulation This pair of projects cover Texture Mapping of MPEG Videos in the OpenGL programs which was later extended to texture map output of another OpenGL program. First screenshots displays my first attempt at OpenGL during summer project work which displays a 3D Room with a computer system and a screen hanging both of which were texture mapped with videos. The second screenshot is output of a MultiMirror Reflection Program achieved using Stencil Buffer.


Fragment Shading on a 3DS Model - Using an existing 3DS Loader
A Simple Ray Tracer - Without Shading, just primary intersection
Shadows on predefined planes - Shadow Maps and Shadow Volumes
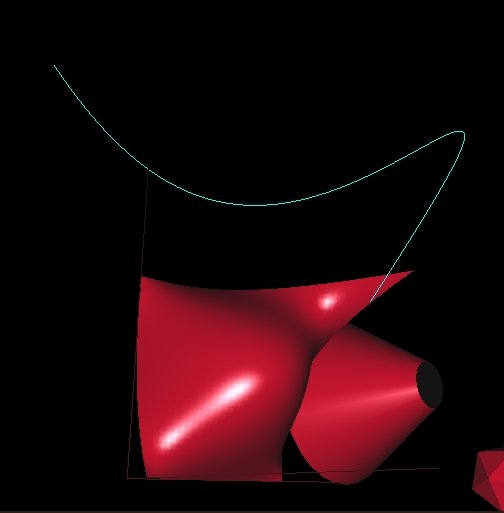
Drawing Curves using OpenGL Evaluators and gluQuadrics and gluNURBS
Improvements in ImageMagick - Changed animate and display utility
Simulation of SourceForge - A Web page enhancing Open Source
Course Registration Portal - A Web Page for online registration
Core - a simple shell, supporting redirections etc.
Database for Automobile Company - As a part of DBMS course
Simple chat program, talk and top (as part of OS Course)